
Test-Time Training (TTT) proposes to adapt a pre-trained network to changing data distributions on-the-fly. In this work, we propose the first TTT method for 3D semantic segmentation, TTT-KD, which models Knowledge Distillation (KD) from foundation models (e.g. DINOv2) as a self-supervised objective for adaptation to distribution shifts at test-time. Given access to paired image-pointcloud (2D-3D) data, we first optimize a 3D segmentation backbone for the main task of semantic segmentation using the pointclouds and the task of 2D → 3D KD by using an off-the-shelf 2D pre-trained foundation model. At test-time, our TTT-KD updates the 3D segmentation backbone for each test sample, by using the self-supervised task of knowledge distillation, before performing the final prediction. Extensive evaluations on multiple indoor and outdoor 3D segmentation benchmarks show the utility of TTT-KD, as it improves performance for both in-distribution (ID) and out-of-distribution (OOD) test datasets. We achieve a gain of up to 13 % mIoU (7 % on average) when the train and test distributions are similar and up to 45 % (20 % on average) when adapting to OOD test samples.

Given paired image-pointcloud data of a 3D scene, TTT-KD , during joint-training, optimizes the parameters of a point or voxel-based 3D backbone, ψ3D , followed by two projectors, ρY and ρ2D. While ρY predicts the semantic label of each point, ρ2D is used for knowledge distillation from a frozen 2D foundation model, ϕ2D. During test-time training, for each test scene, we perform several optimization steps on the self-supervised task of knowledge distillation to fine-tune the parameters of the 3D backbone. Lastly, during inference, we freeze all parameters of the model to perform the final prediction. By improving on the knowledge distillation task during TTT, the model adapts to out-of-distribution 3D scenes different from the source data the model was initially trained on. On the off-line version of our algorithm, we reset the parameter updates after each inference step. On the online version, we keep the updates after each inference, allowing us to reduce the number of TTT steps required.
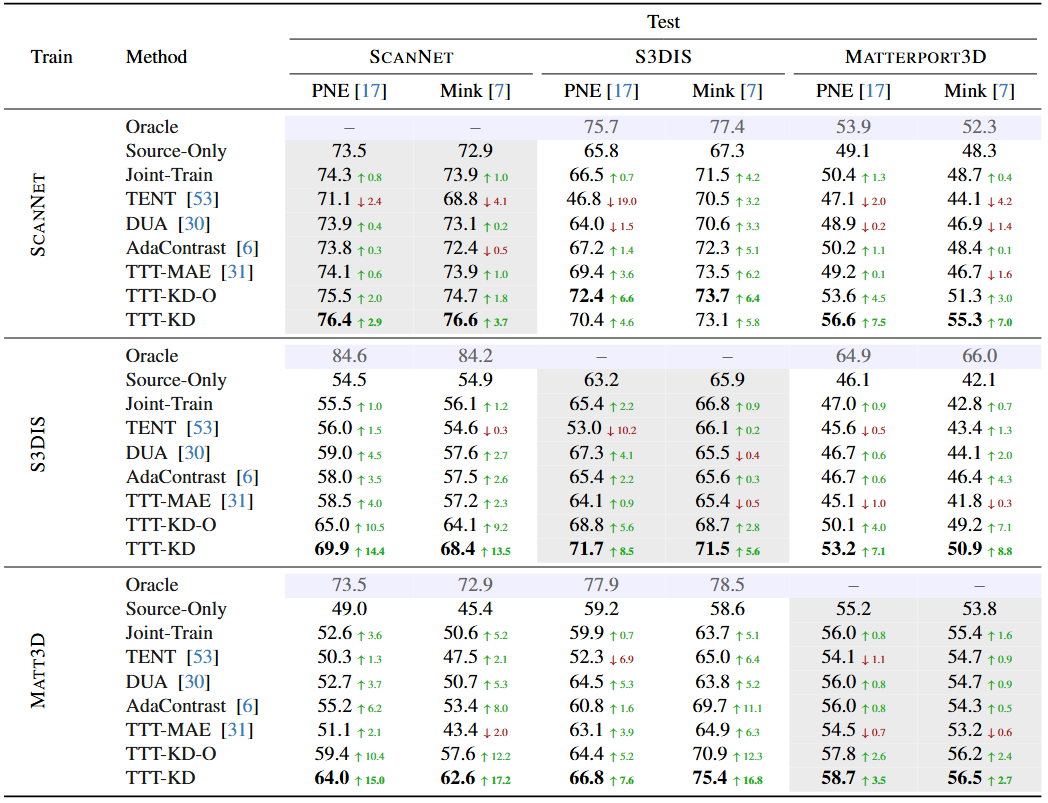
Joint-training. Our results show that for all datasets and both 3D backbones, Joint-Train always provides an improvement over the Source-Only model.
In-distribution. When testing on in-distribution data, train and test on the same dataset, our algorithm, TTT-KD, provides significant improvements for all three datasets and all 3D backbones.
Out-of-distribution. When we look at the performance of the Source-Only models when tested on ODD data, as expected, the performance drops significantly when compared with an Oracle model trained on ID data. Our TTT-KD algorithm, on the other hand, is able to reduce this gap, increasing significantly the performance of all models and even obtaining better performance than the Oracle model as in the ScanNet → Matterport3D experiment.
Comparison to baselines. When compared to TENT, DUA, AdaContrast, and TTT-MAE, although these baselines can provide some adaptation, TTT-KD has a clear advantage, surpassing them by a large margin.
Backbone agnostic. When we analyze the performance of our method on different backbones, we see a consistent improvement in all setups. This indicates that our method is independent of the 3D backbone used.

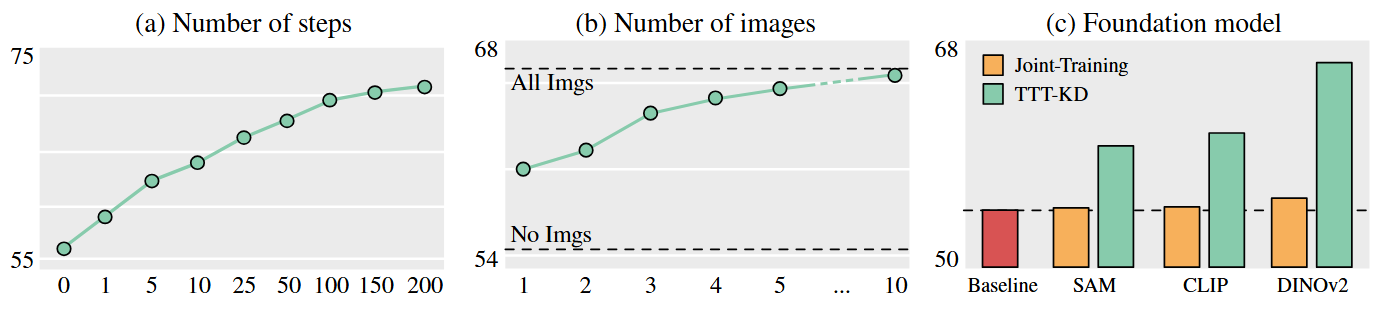
Number of steps. We measure the performance of our TTT-KD algorithm in relationship to the number of TTT steps and plot the results in Fig. (a). We see that the mIoU increases with the number of TTT updates, and saturates at 200 steps. However, relative improvement is reduced after 100 steps.
Number of images. We measure the performance of our method w.r.t. the number of images used for KD. Fig. (b) presents the results of this experiment. We can see that even when only a single image is used (most of the points in the scene do not have a paired image), we can achieve a boost in mIoU. Moreover, we can see that the improvement saturates for 5 images when the improvement obtained by including an additional image is reduced.
Foundation model. We compare the foundation model used in our main experiments, DINOv2, to a CLIP model, and to a SAM model, and provide the results in Fig. (c). Our TTT-KD is also able to provide considerable performance gains while using CLIP or SAM in our pipeline.
@article{weijler2025tttkd,
title={TTT-KD: Test-Time Training for 3D Semantic Segmentation through Knowledge Distillation from Foundation Models},
author={Weijler, L. and Mirza, M. J. and Sick, L. and Ekkazan, C. and Hermosilla, P.},
journal={International Conference on 3D Vision (3DV)},
year={2025}
}