
Self-Supervised Feature Visualization using PCA.
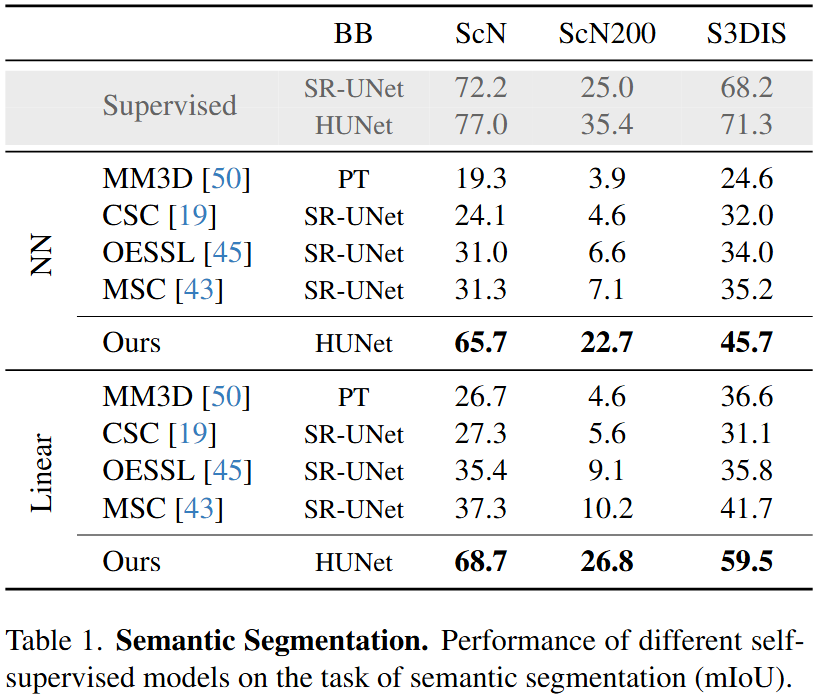
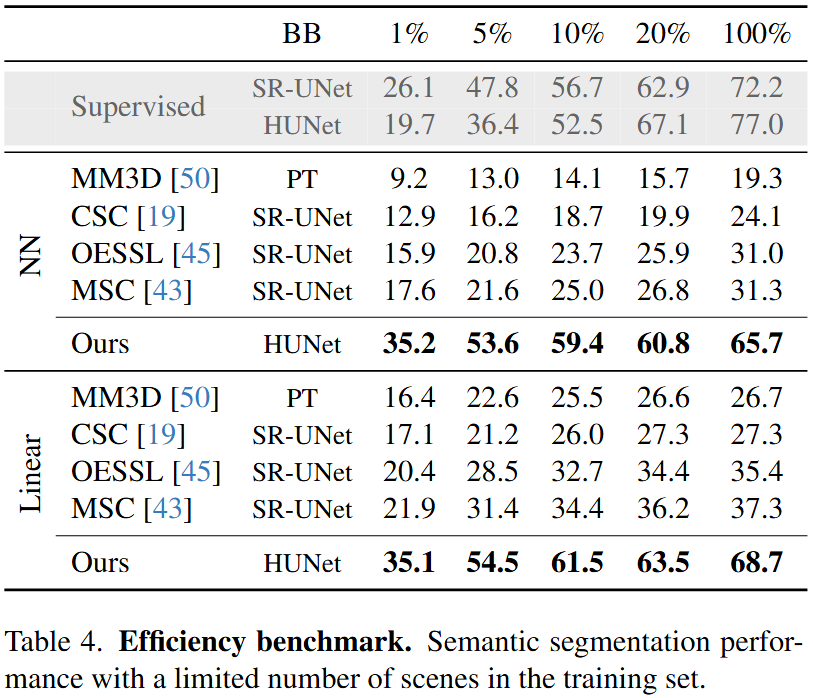
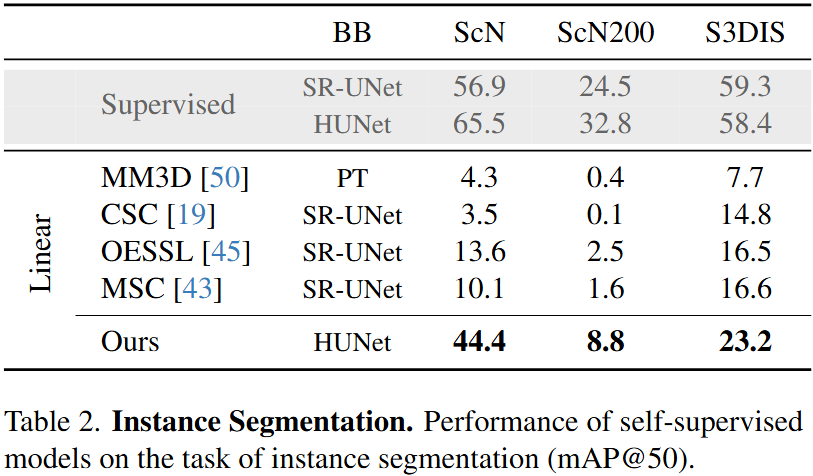
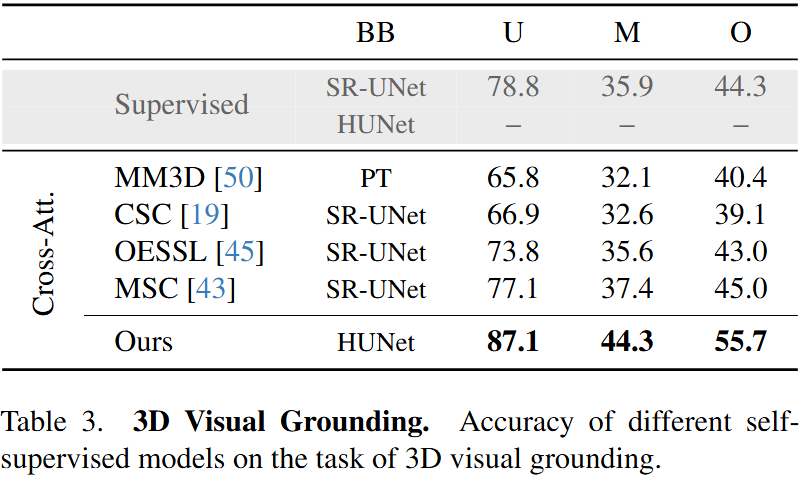
Self-supervised learning has transformed 2D computer vision by enabling models trained on large, unannotated datasets to provide versatile off-the-shelf features that perform similarly to models trained with labels. However, in 3D scene understanding, self-supervised methods are typically only used as a weight initialization step for task-specific fine-tuning, limiting their utility for general-purpose feature extraction. This paper addresses this shortcoming by proposing a robust evaluation protocol specifically designed to assess the quality of self-supervised features for 3D scene understanding. Our protocol uses multi-resolution feature sampling of hierarchical models to create rich point-level representations that capture the semantic capabilities of the model and, hence, are suitable for evaluation with linear probing and nearest-neighbor methods. Furthermore, we introduce the first self-supervised model that performs similarly to supervised models when only off-the-shelf features are used in a linear probing setup. In particular, our model is trained natively in 3D with a novel self-supervised approach based on a Masked Scene Modeling objective, which reconstructs deep features of masked patches in a bottom-up manner and is specifically tailored to hierarchical 3D models. Our experiments not only demonstrate that our method achieves competitive performance to supervised models, but also surpasses existing self-supervised approaches by a large margin.
Existing self-supervised methods for 3D scene understanding...

Our method receives as input a 3D scene represented as a pointcloud, (a). The scene is voxelized into two different views, (b), and then further cropped and masked, (c). The student model first encodes the cropped views and then adds the masked voxels with a learnable token, (d). The decoder processes the cropped views and reconstructs deep features of the masked tokens, (e). The loss is computed in a cross-view manner where the target features, (f), are obtained from a teacher model which parameters are updated with the Exponential Moving Average (EMA) of the parameters of the student, (g).
We pre-train our self-supervised model on the Scannet dataset. We then freeze our model and evaluate the representations learned with a linear probing and a nearest-neighbor evaluation protocol (see paper for more details).
We reduce the point features obtained with our self-supervised model to three dimensions using PCA and visualize them as colors. Features learned by our model are semantic-aware, which is visible from the color separation: Similar objects result in similar features while different objects result in different features.

@article{hermosilla2025msm,
title={Masked Scene Modeling: Narrowing the Gap Between Supervised and Self-Supervised Learning in 3D Scene Understanding},
author={Hermosilla, P. and Stippel, C. and Sick, L.},
journal={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025},
}